Discovery rules
Discovery rules represent a user-defined set of parameters that the discovery process follows to find specific types of data in specific sources. This process requires an imported environment to function, and also preferred BizDataX discoverers installed which happens automatically when installing the BizDataX Portal.
| Table of contents |
|---|
| Discovery Rules Overview List |
| Create Rule |
| View Findings |
| Edit Rule |
| Run discovery |
| Delete Rule |
| Reporting |
| Discovery History |
Discovery Rules Overview List
All rules currently contained in the project can be viewed on the rules list, the landing page of the rules functionality. It contains a table detailing every rule in the project. Information necessary for quickly identifying rules are present such as the rule name, fundamental data name, and what type of discoverer the rule uses, and on which scope of the data. The number of discovery findings of each status (sensitive, not sensitive, and unknown) are also presented to provide a glance at the results of the rule.
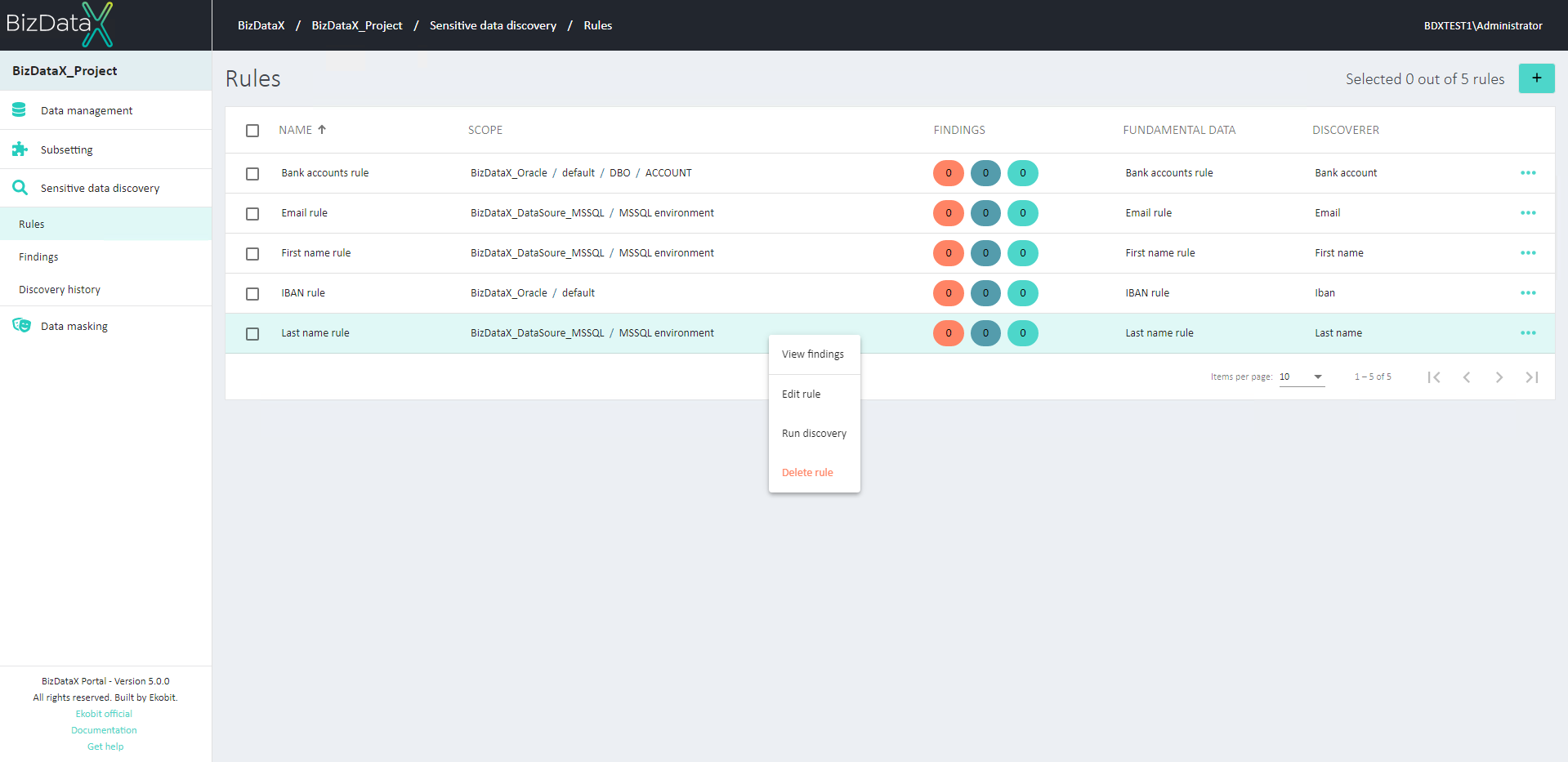 Figure 1: Discovery Rules Overview List
Figure 1: Discovery Rules Overview List
On the menu on the right available options are:
- View Findings - To view the findings of the rule
- Run discovery
- Edit Rule
- Delete Rule
Use checkboxes to:
- Run discovery on selected rules
- View findings from selected rules
- Delete selected rules.
To start the discovery process, select one or more rules and select option Run discovery on the right. You can view previous discovery executions by clicking the book button in the top right corner of the page which will take you to the Discovery history page.
Create Rule
If there are no rules, the discovery rules list is empty.
 Figure 2: No Rules
Figure 2: No Rules
To create a new rule, click on the Create rule button in the top right corner.
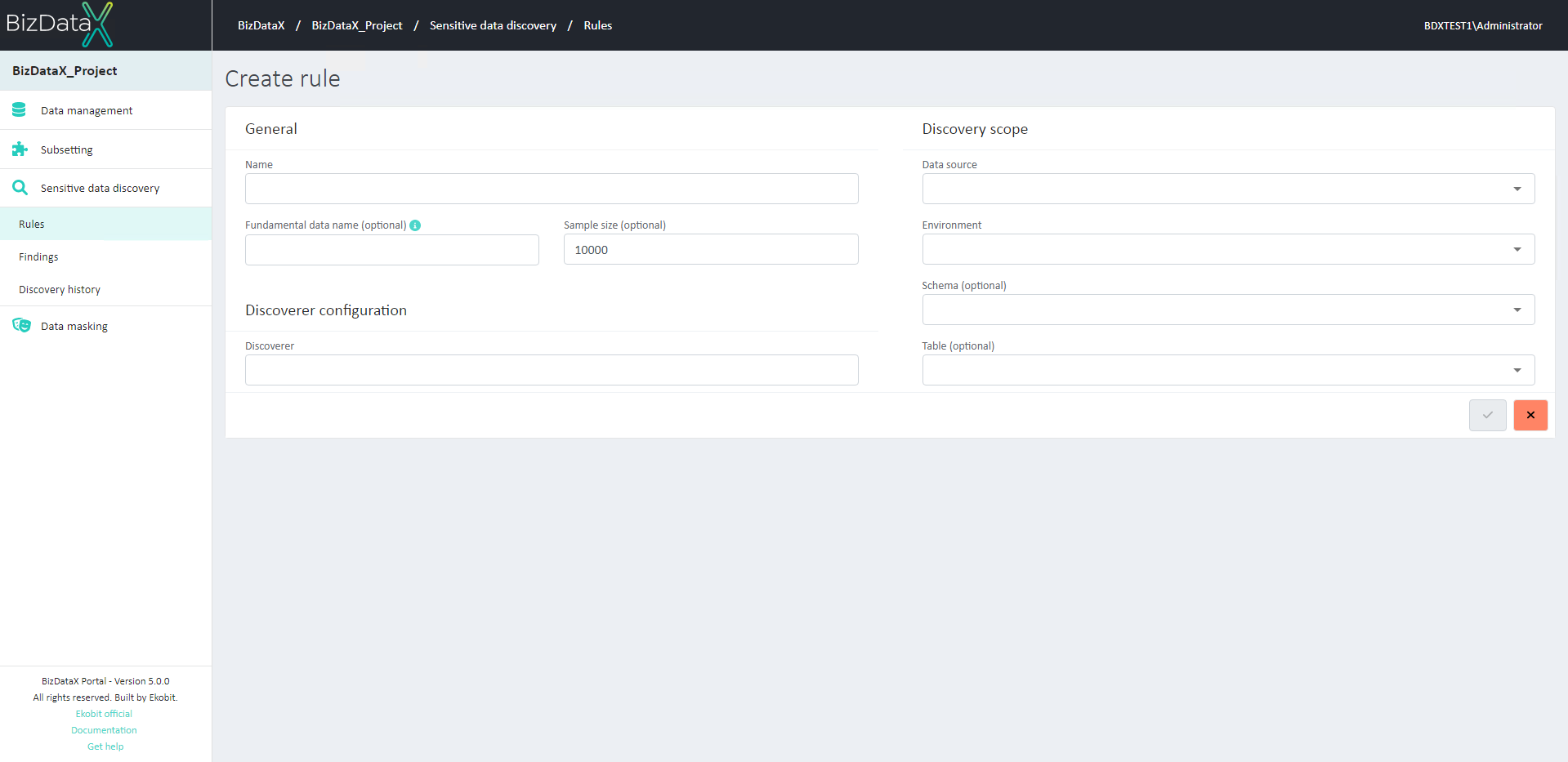 Figure 3: Create Rules
Figure 3: Create Rules
When creating a new rule, user must enter the necessary parameters: General
Name - Unique name of the rule. Make sure to name them in such a way that they are easily distinguishable from each other, especially if you're creating more detailed rules, multiple rules in the same environment, etc. (e.g. 'First Names')
Fundamental data name - basic type of data in database columns, and if they are not entered, they will be the same as the rule name by default
Sample size - Amount of data that will be analyzed.
The discovery process only analyzes a part of the data in the database since analyzing every piece of data could drastically increase the duration of the sensitive data discovery without much gain. User has here an option to increase or decrease the amount of data that is being analyzed. A larger sample size results in a better quality of data and thus more precise sensitive data discovery results, but it also increases the duration of the process. Smaller sample size means we get the results faster but at the cost of data quality. The default sample size of
10000records has proven to provide good quality of data in a reasonable amount of time.
Discoverer configuration
Discoverer - Each BizDataX discoverer searches for specific types of data, so user needs to choose a discoverer appropriate for desired rule. Discoverers are selected from a list and they are grouped by categories. The description of the discoverer can be seen below the name of the discoverer to help differentiate between similar discoverers.
e.g. For searching Names user can choose between several discoverers, where each has its own unique use. In case user want to search for everything that looks like a First name (regardless of whether it also looks like the last name or another type of sensitive data as well), user must choose the
First namediscoverer.Value - If chosen discoverer contains Names this field will be open to enter Country code. User can enter a country code so sensitive data discovery only searches for the first names of a specific country. (e.g. If user want to look only for first names from the United States, 'US' country code must be entered)
Discovery scope
- Data source - Data source is mandatory field. User must choose data source from drop-down list. To search for sensitive data in the entire environment, user only enters Data source.
- Environment - To search for sensitive data through all Schemas, user enters Data source and Environment from drop-down list. This field is optional.
- Schema - To search for sensitive data through all tables of a specific schema user must enter Schema. This field is optional and Environment must be entered.
- Table - To search for sensitive data through specific table user must enter Table name from drop-down list. This field is optional and Schema must be entered.
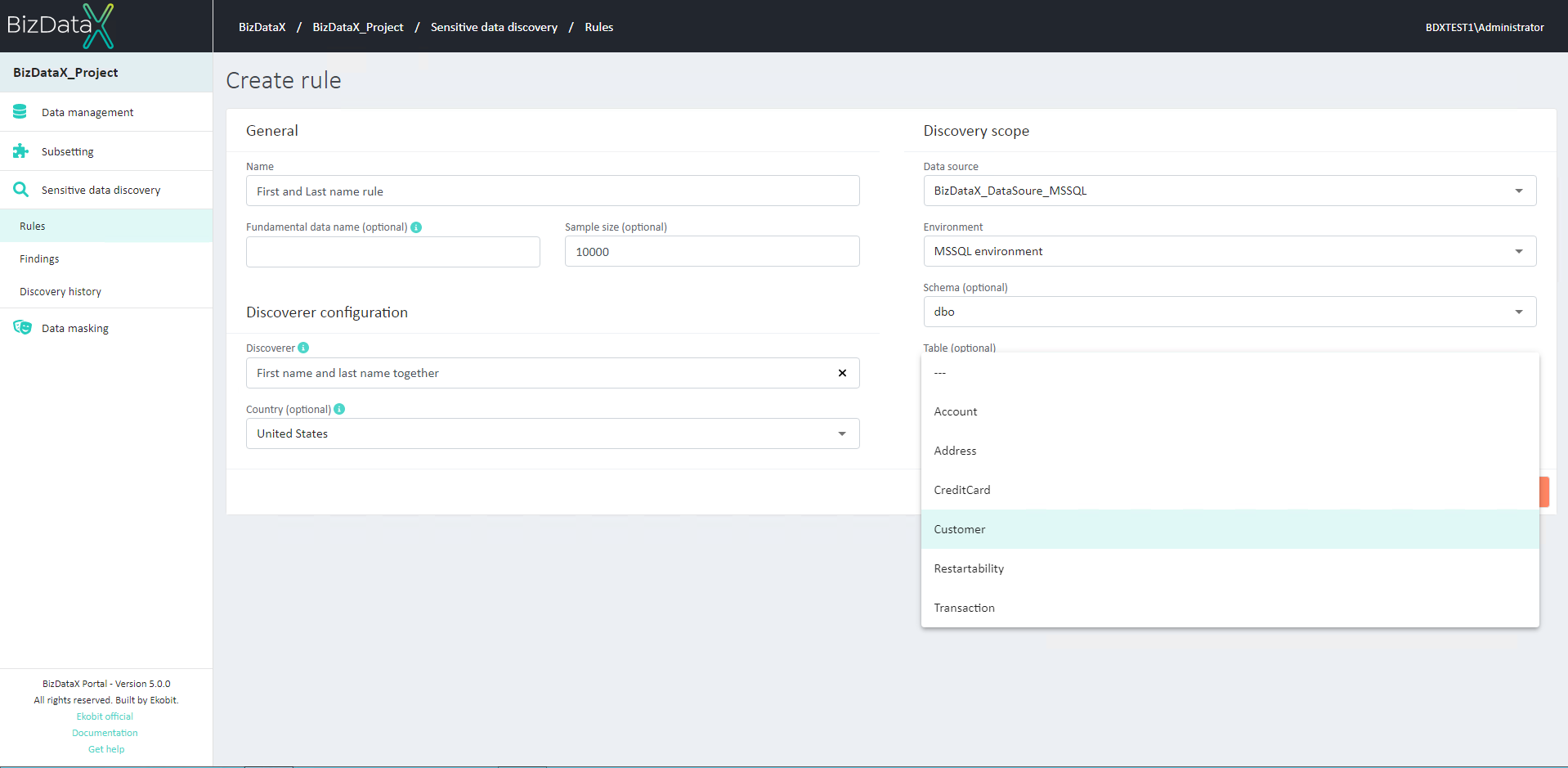 Figure 4: Discovery scope
Figure 4: Discovery scope
Note: Performance and quality of data can also be affected by the data source analysis settings. The default options in both of these settings are the recommended settings which should work well with most tables.
Once all the information is set, select the Create rule button in the bottom right of the page to create the rule or edit an existing one. You can cancel the creation/edit of a rule at any time by clicking the Cancel button.
View Findings
Selecting option from table menu 'View Finding' system will open Discovery Finding overview list screen.
Edit Rule
It is possible to Edit an existing rule when rule is already created.
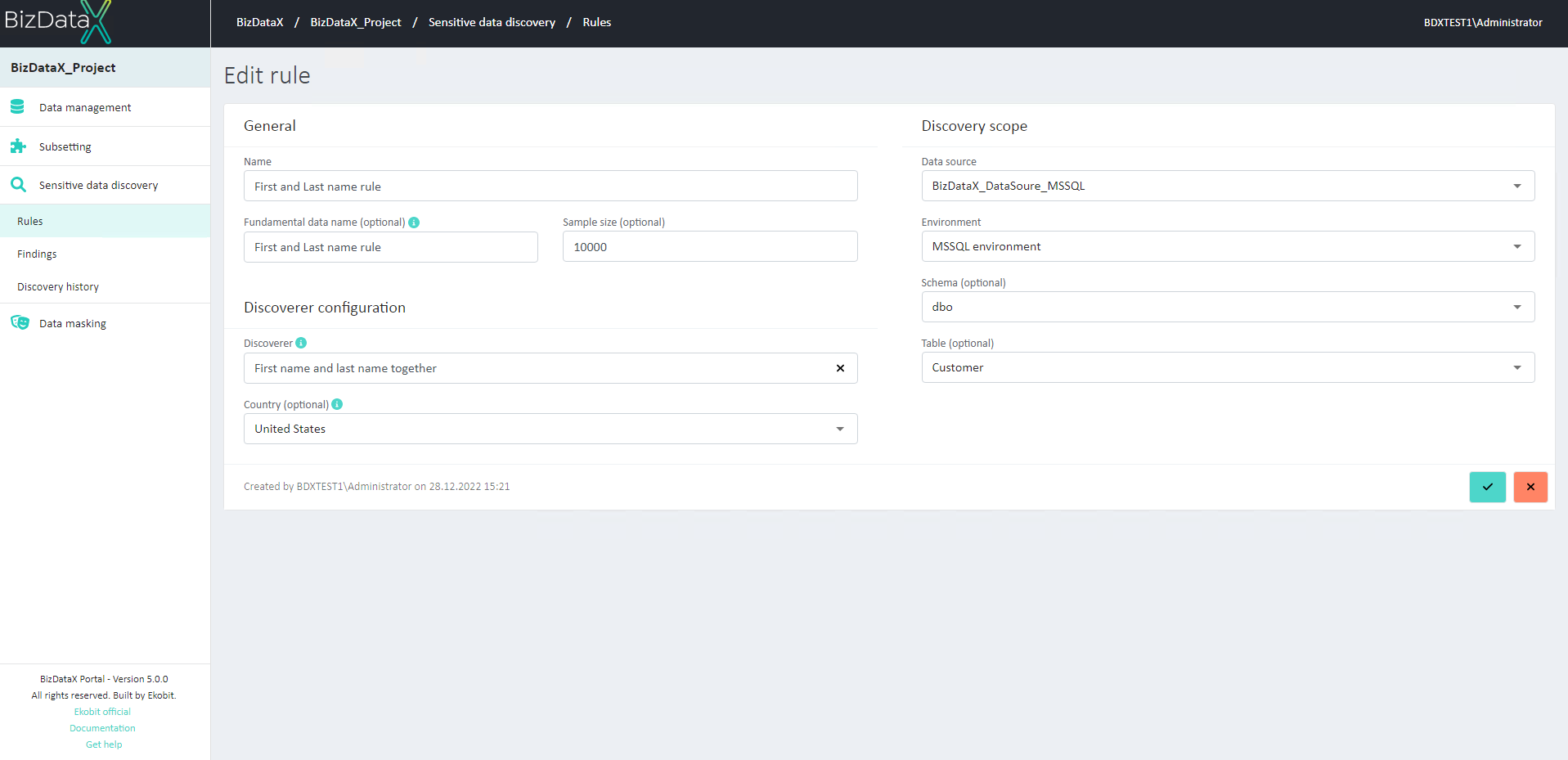 Figure 5: Edit rule
Figure 5: Edit rule
In context ‘Edit’ rule all fields are editable.
To confirm amending click on Commit button. To cancel the editing an existing rule, click on the Cancel button.
After rule is edited, system will be redirected to the Discovery rule overview list where user can see all created rules.
Run discovery
Once sensitive data discovery rules is created, discovery finding process to generate findings can be started.
On Discovery rules overview list select rule to run and select on table menu option Run discovery. To run the discovery process with more than one rule, select the rules you want on the checkboxes on the left side of the rule list, and then select the Run discovery on selected rules option.
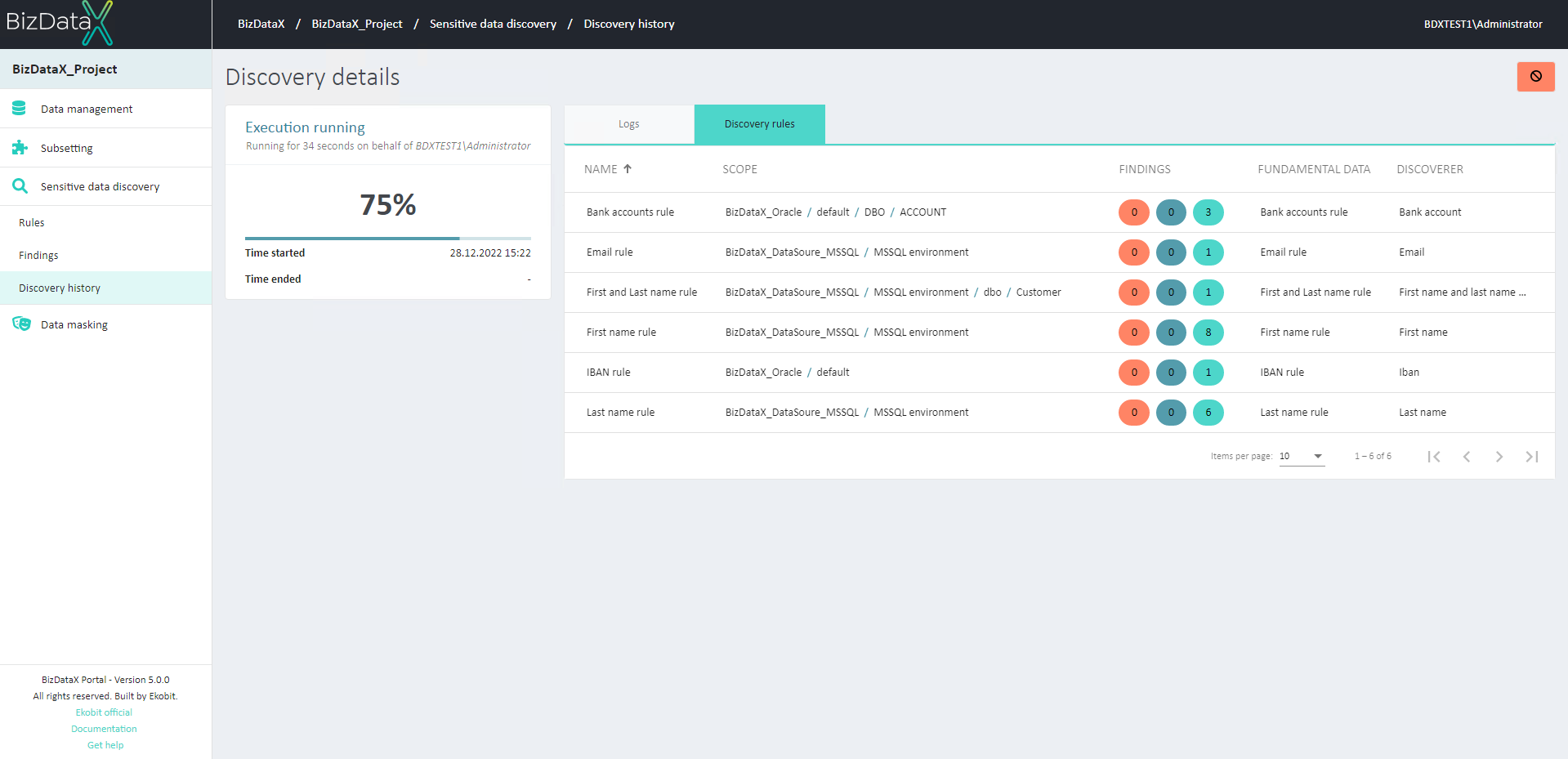 Figure 6: Run Discovery
Figure 6: Run Discovery
Once the sensitive data discovery is complete, every finding will have the default Unknown status assigned. This can be seen on the rule list and can be used to quickly check the number of findings of a single rule. The status of findings can be changed in the Discovery Findings Overview List.
Once the sensitive data discovery is started, you will be redirected to the Discovery details page.
If sensitive data discovery is still running, you can track the progress using the progress bar and real-time log. You can stop the sensitive data discovery process by using the Abort button on the right. Options to re-run sensitive data discovery, represented by the Re-run button, and a shortcut to generated findings, represented by the magnifier button, can also be found here.
Delete Rule
If Rule is no needed user can select on Discovery rules overview list one or more rules, by using checkboxes, to Delete it. A confirmation message appears before deleting.
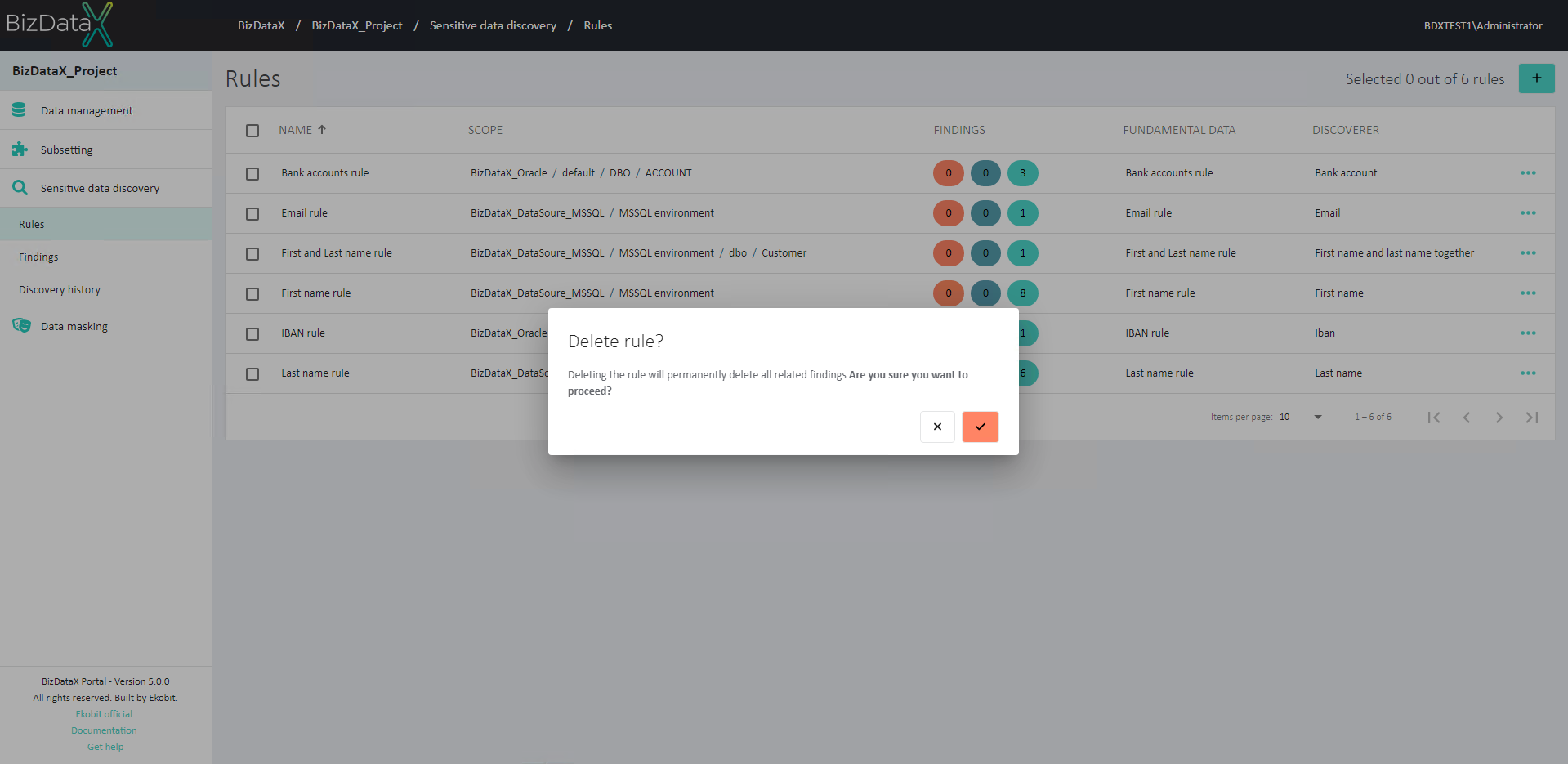 Figure 7: Delete rule confirmation message
Figure 7: Delete rule confirmation message
Discovery History
All previous discovery executions can be viewed on Discovery History Overview List